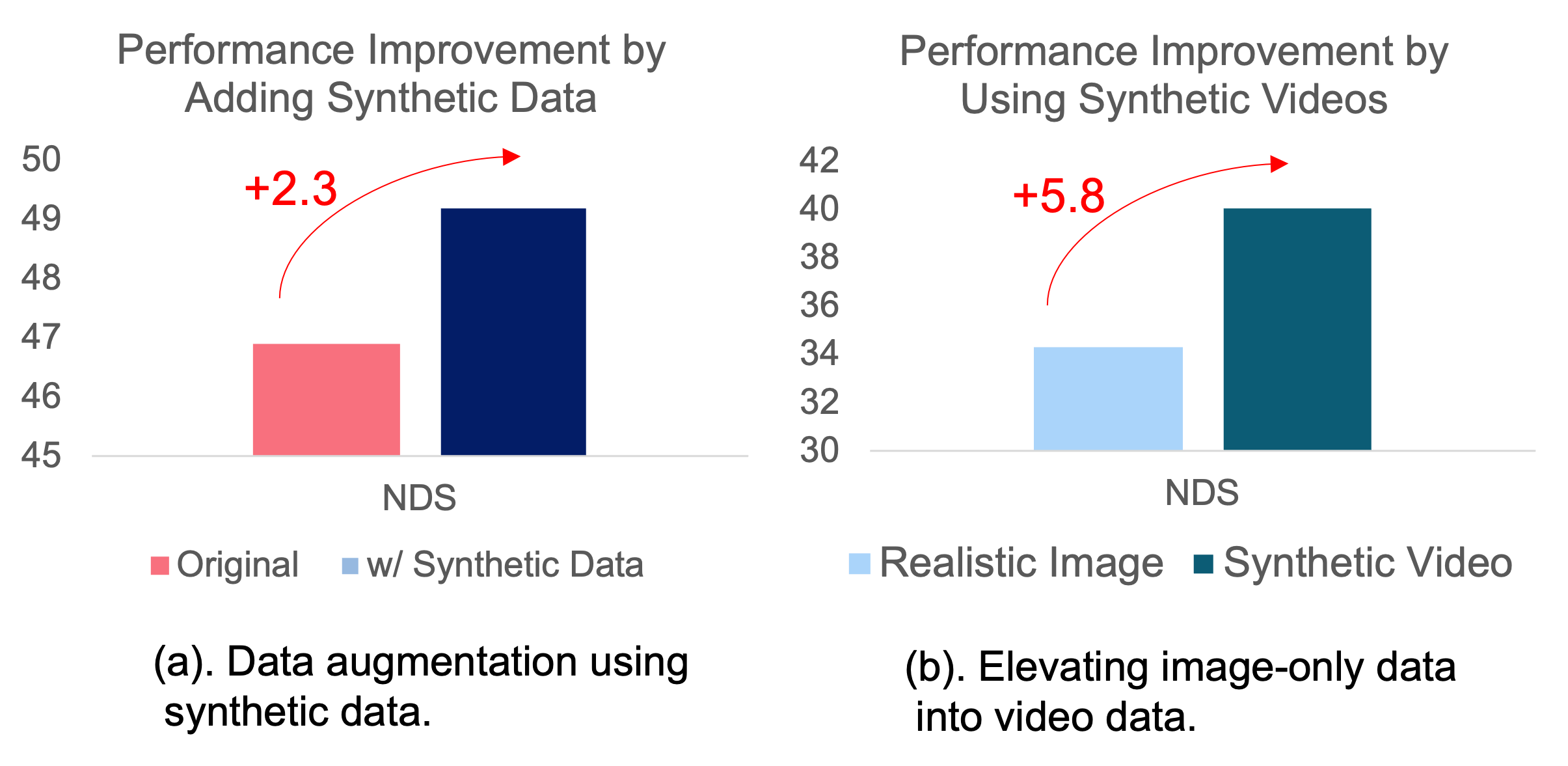
Generating Multi-View and Controllable Videos for Autonoumous Driving
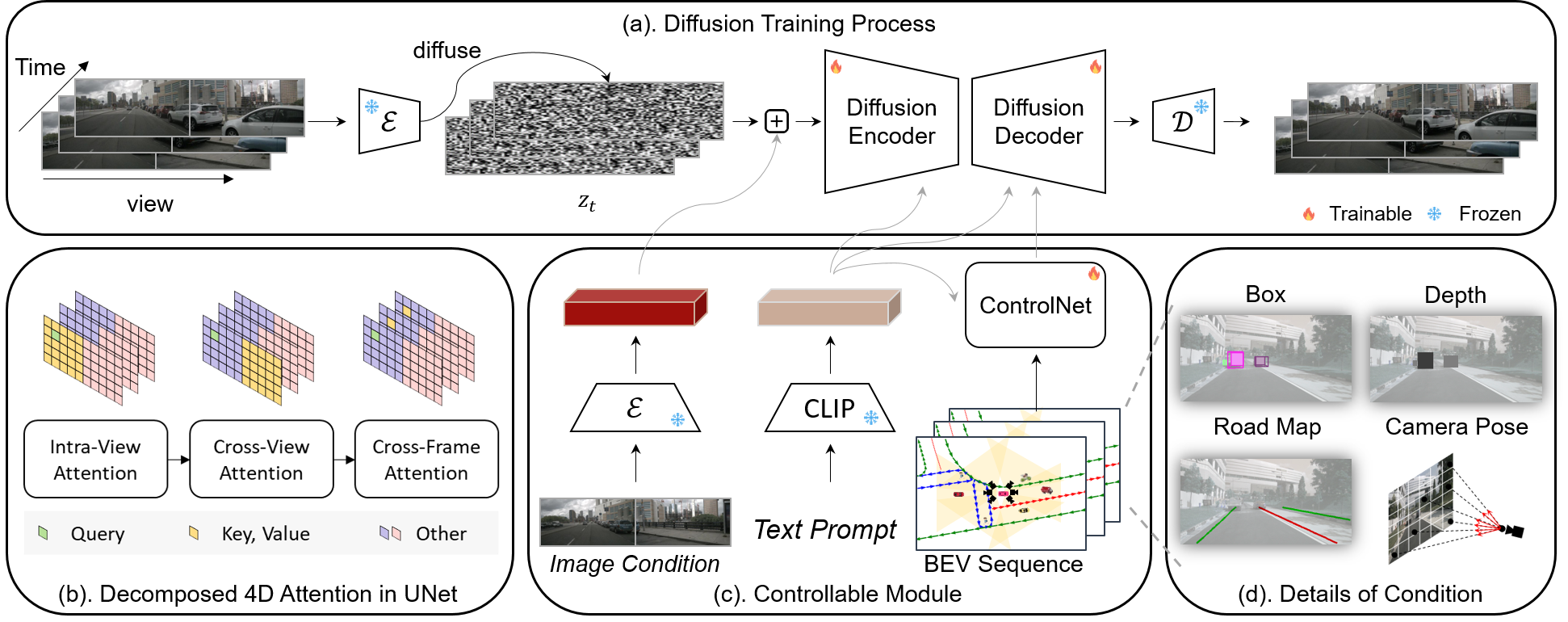
Overview of Panacea. (a). The diffusion training process of Panacea, enabled by a diffusion encoder and decoder with the decomposed 4D attention module. (b). The decomposed 4D attention module comprises three components: intra-view attention for spatial processing within individual views, cross-view attention to engage with adjacent views, and cross-frame attention for temporal processing. (c). Controllable module for the integration of diverse signals. The image conditions are derived from a frozen VAE encoder and combined with diffused noises. The text prompts are processed through a frozen CLIP encoder, while BEV sequences are handled via ControlNet. (d). The details of BEV layout sequences, including projected bounding boxes, object depths, road maps and camera pose.
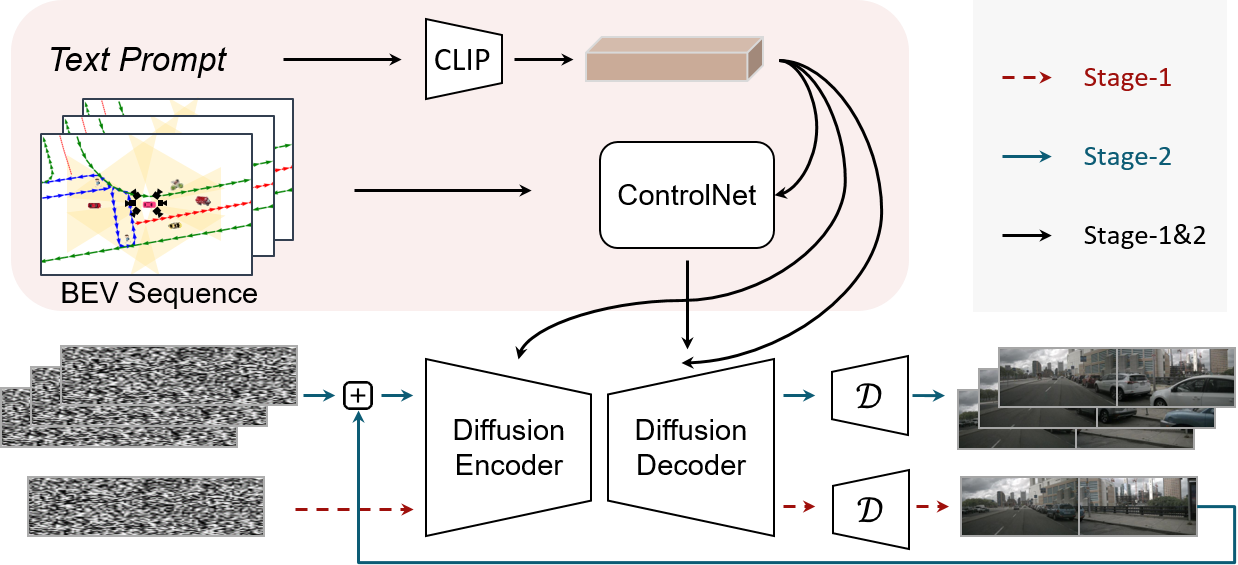
The two-stage inference pipeline of Panacea. Its two-stage process begins by creating multi-view images with BEV layouts, followed by using these images, along with subsequent BEV layouts, to facilitate the generation of following frames.